RivieraDev s’est agrandie cette année avec une journée supplémentaire le mercredi pour une journée « deep dive » elle a permis de placer deux conférences qui approfondissent un sujet en particulier.
Les grands thèmes présents cette année ont été le Machine Learning, le devops-cloud-containers et l’architecture applicative en général et le développement web (JS). Cette orientation devops vient en partie du fait que le sponsor principal est Red Hat. Lequel a disposé d’une track « JUD Con » le long de ces 3 journées.
Les grands thèmes presque totalement absents furent Java ( :’-/ ) , et l’agilité.

 Une grosse séance d’introduction au Deep Learning. Qui commence calmement avec des définitions et finit dans les dérivées partielles de fonctions intégrales.
La différence entre les systèmes experts et le deep learning est que le premier dépends du déterminisme d’un ensemble de règles préétablies alors que le deuxième est plus défini de manière floue (d’où l’accident survenu récemment)
et TUGDUAL GRALL
Le but du projet présenté : End to End distributed Pipeline for sort of Big Data, Kafka, SparkML, MapR : Machine Learning.
Carol a présenté son travail également en trois articles sur le site de MapR.
C’était une présentation en deux parties :
Une grosse séance d’introduction au Deep Learning. Qui commence calmement avec des définitions et finit dans les dérivées partielles de fonctions intégrales.
La différence entre les systèmes experts et le deep learning est que le premier dépends du déterminisme d’un ensemble de règles préétablies alors que le deuxième est plus défini de manière floue (d’où l’accident survenu récemment)
et TUGDUAL GRALL
Le but du projet présenté : End to End distributed Pipeline for sort of Big Data, Kafka, SparkML, MapR : Machine Learning.
Carol a présenté son travail également en trois articles sur le site de MapR.
C’était une présentation en deux parties :
 Stephen, par son activité de développeur Debian, maintient plusieurs paquets et suit de très près les patchs de sécurité à mettre en oeuvre.
Il a présenté très clairement les conséquences d’une découverte d’une faille de sécurité. Notamment les conditions de divulgations de cette faille à un public restreint pour une période limitée dans le temps.
Cet aspect de divulgation soulève des questions de confiance, qui peuvent être réglé par la contractualisation lorsque l’enjeu le justifie.
Avec le talent d’orateur qu’on lui connait, son talk parlait de l’évolution des technologies, le fait qu’une technologie chassant une autre, la documentation de l’infrastructure et de l’architecture logicielle peut se perdre par obsolescence. Il propose alors de monter d’un niveau dans l’abstraction et mettre en place un système de documentation des briques de notre infra par assemblage de concepts agnostique : des nœuds, (les serveurs de DB, d’applications) , relié par des liens (la couche réseaux). Le but est garder un fil rouge qui nous guiderait lors de la maintenance en cas d’incident mais aussi lors de migration de technologies.
De plus il propose que ces informations soient portés par des fichiers de configuration dédiés, rédigés dans un DSL conçu spécifiquement dans ce but, en cours de publication, et présenté par ailleurs lors de cette édition du Riviera dans un talk sur la description de dépendances de services sémantique. (talk auquel je n’ai pas pu assisté 🙁 )
Steven Pousty s’intéresse aux architectures logicielles et dans son talk fort guilleret, il a mené une discussion sur les questions soulevées par les grands choix d’architecture. Il laisse chacun à ses réflexions au final.
Un premier message est qu’il ne faut pas céder aux sirènes de la « hype » sur une techno ou une autre. Et se livrer à une introspection :
Mario a présenté une « typologie de topologie » de containers. Il en a identifié 14 sur son github.
Il travaille sur Openshift et Eclipse Che qui est l’éditeur intégré dans Openshift.
Du temps de la hype docker, différents patterns émergent selon la manière de builder et déployer les containers.
3 catégories :
Stephen, par son activité de développeur Debian, maintient plusieurs paquets et suit de très près les patchs de sécurité à mettre en oeuvre.
Il a présenté très clairement les conséquences d’une découverte d’une faille de sécurité. Notamment les conditions de divulgations de cette faille à un public restreint pour une période limitée dans le temps.
Cet aspect de divulgation soulève des questions de confiance, qui peuvent être réglé par la contractualisation lorsque l’enjeu le justifie.
Avec le talent d’orateur qu’on lui connait, son talk parlait de l’évolution des technologies, le fait qu’une technologie chassant une autre, la documentation de l’infrastructure et de l’architecture logicielle peut se perdre par obsolescence. Il propose alors de monter d’un niveau dans l’abstraction et mettre en place un système de documentation des briques de notre infra par assemblage de concepts agnostique : des nœuds, (les serveurs de DB, d’applications) , relié par des liens (la couche réseaux). Le but est garder un fil rouge qui nous guiderait lors de la maintenance en cas d’incident mais aussi lors de migration de technologies.
De plus il propose que ces informations soient portés par des fichiers de configuration dédiés, rédigés dans un DSL conçu spécifiquement dans ce but, en cours de publication, et présenté par ailleurs lors de cette édition du Riviera dans un talk sur la description de dépendances de services sémantique. (talk auquel je n’ai pas pu assisté 🙁 )
Steven Pousty s’intéresse aux architectures logicielles et dans son talk fort guilleret, il a mené une discussion sur les questions soulevées par les grands choix d’architecture. Il laisse chacun à ses réflexions au final.
Un premier message est qu’il ne faut pas céder aux sirènes de la « hype » sur une techno ou une autre. Et se livrer à une introspection :
Mario a présenté une « typologie de topologie » de containers. Il en a identifié 14 sur son github.
Il travaille sur Openshift et Eclipse Che qui est l’éditeur intégré dans Openshift.
Du temps de la hype docker, différents patterns émergent selon la manière de builder et déployer les containers.
3 catégories :
 Quelques exemples :
Paulo est contributeur pour Red Hat sur Vert.X. Sa présentation est disponible sur son github.
C’était une demo avec l’application « Pong As A Service » : dans une page web, on joue au pong contre un robot qui utilise websocket pour renvoyer la balle.
Mathilde Lemée est actuellement CTO de jolimoi.com. Elle a cependant parlé de son expérience sur un chatbot de recommandation de vins.
Or, les recommandations sont critiques dans un process de vente :
amazon : 35%. des ventes en 2014.
Netflix :
et FABIEN JUIF
Ils ont présenté une appli de todolist et le chemin de refactoring qu’ils ont suivi pour l’améliorer.
Les slides de m4dz.
Dans son talk m4dz revient sur les fondamentaux de l’utilisation du chiffrement.
D’abord selon le type de données, il faut identifier celles qui sont « sensibles » au titre de la RGPD, par exemple, ou au titre du secret professionnel.
La crypto en tant que telle est utilisé :
1. pour les hash, c’est à dire les calculs de sommes de contrôle ou d’unicité.
2. pour dissimuler une donnée qu’on désire tout de même stocker.
3. pour échanger des clés de chiffrement au moment où c’est nécessaire pour par exemple un dialogue ultérieur.
4. pour générer un signature en chiffrant avec sa clé privé.
Il évoque le salage rendu nécessaire pour améliorer le chiffrement en diminuant les risques de répétition et il existe des best practices du bon sel à ajouter à sa donnée avant chiffrement.
Il reprends la typologie de chiffrement symétrique /asymétrique:
symétrique : AES,IDEA, Blowfish, car DES est aujourd’hui compromis..
La leçon est : ne pas inventer soi-même d' »algoryme » (sic) de crypto et utiliser des solutions standards et open source.
Quelques exemples :
Paulo est contributeur pour Red Hat sur Vert.X. Sa présentation est disponible sur son github.
C’était une demo avec l’application « Pong As A Service » : dans une page web, on joue au pong contre un robot qui utilise websocket pour renvoyer la balle.
Mathilde Lemée est actuellement CTO de jolimoi.com. Elle a cependant parlé de son expérience sur un chatbot de recommandation de vins.
Or, les recommandations sont critiques dans un process de vente :
amazon : 35%. des ventes en 2014.
Netflix :
et FABIEN JUIF
Ils ont présenté une appli de todolist et le chemin de refactoring qu’ils ont suivi pour l’améliorer.
Les slides de m4dz.
Dans son talk m4dz revient sur les fondamentaux de l’utilisation du chiffrement.
D’abord selon le type de données, il faut identifier celles qui sont « sensibles » au titre de la RGPD, par exemple, ou au titre du secret professionnel.
La crypto en tant que telle est utilisé :
1. pour les hash, c’est à dire les calculs de sommes de contrôle ou d’unicité.
2. pour dissimuler une donnée qu’on désire tout de même stocker.
3. pour échanger des clés de chiffrement au moment où c’est nécessaire pour par exemple un dialogue ultérieur.
4. pour générer un signature en chiffrant avec sa clé privé.
Il évoque le salage rendu nécessaire pour améliorer le chiffrement en diminuant les risques de répétition et il existe des best practices du bon sel à ajouter à sa donnée avant chiffrement.
Il reprends la typologie de chiffrement symétrique /asymétrique:
symétrique : AES,IDEA, Blowfish, car DES est aujourd’hui compromis..
La leçon est : ne pas inventer soi-même d' »algoryme » (sic) de crypto et utiliser des solutions standards et open source.
 Une keynote où Mathilde a narré son expérience de CTO dans la startup de recommandation de produits de beauté Jolimoi, et comment elle a découvert les aspects du métier de CTO en tant que développeuse.
et CORENTIN COCOUAL
Une très agréable présentation autour d’une appli de couche sirop qui veut migrer vers une appli de cul de chouette.
Mais j’ai pas compris les règles.
SpeakerDeck : les 10 choses à ne pas faire avec jenkins.
Une keynote où Mathilde a narré son expérience de CTO dans la startup de recommandation de produits de beauté Jolimoi, et comment elle a découvert les aspects du métier de CTO en tant que développeuse.
et CORENTIN COCOUAL
Une très agréable présentation autour d’une appli de couche sirop qui veut migrer vers une appli de cul de chouette.
Mais j’ai pas compris les règles.
SpeakerDeck : les 10 choses à ne pas faire avec jenkins.
 Mes notes en anglais (as he spoke english, i didn’t translate)
Roland est Solutions engineer chez Amadeus. Sa presentation et sa matière première se retrouvent sur son repository banana-box.
Il travaille sur Openshift et a discuté du comportement des containers vis-à-vis des JVM.
Mes notes en anglais (as he spoke english, i didn’t translate)
Roland est Solutions engineer chez Amadeus. Sa presentation et sa matière première se retrouvent sur son repository banana-box.
Il travaille sur Openshift et a discuté du comportement des containers vis-à-vis des JVM.
 La box, c’est un container au sens Docker. Le talk discute des problématiques de sizing de cette banana box : le cpu et la mémoire.
Pour la mémoire, il faut faire usage des ergonomics de la JVM. Initialement la JVM s’auto configure en utilisant le contexte du l’Operating System de l’hôte. Des paramètres – flags existent pour modifier ce comportement du Garbage Collector de la JVM et il est important de noter qu’ils évoluent entre la JVM 8 et la JVM 11.
De même des options Docker fonctionnent sur JVM v11 (et non sur la v8) car cette version améliore le support des cgroups de linux qui font apparaître localement des ressources globales pour la mémoire et le cpu. :
Les slides du talk sont sur slideshare.
C’était un retour d’expérience sur la mise en oeuvre d’Openshift dans une grande compagnie d’assurance.
La motivation du projet était d’internaliser une infrastructure de hosting afin de reprendre en main notamment la gouvernance des multiples sites internet que la société a pu publié à l’initiative de ses différents services communications et marketings.
La box, c’est un container au sens Docker. Le talk discute des problématiques de sizing de cette banana box : le cpu et la mémoire.
Pour la mémoire, il faut faire usage des ergonomics de la JVM. Initialement la JVM s’auto configure en utilisant le contexte du l’Operating System de l’hôte. Des paramètres – flags existent pour modifier ce comportement du Garbage Collector de la JVM et il est important de noter qu’ils évoluent entre la JVM 8 et la JVM 11.
De même des options Docker fonctionnent sur JVM v11 (et non sur la v8) car cette version améliore le support des cgroups de linux qui font apparaître localement des ressources globales pour la mémoire et le cpu. :
Les slides du talk sont sur slideshare.
C’était un retour d’expérience sur la mise en oeuvre d’Openshift dans une grande compagnie d’assurance.
La motivation du projet était d’internaliser une infrastructure de hosting afin de reprendre en main notamment la gouvernance des multiples sites internet que la société a pu publié à l’initiative de ses différents services communications et marketings.

Mercredi 16 mai : Journée Deep-Dive, machine learning
FROM 0 TO DEEP LEARNING IN 3 HOURS
YANNIS BRESle pionnier : la reconnaissance de caractères
La première application des réseaux de neurones fut la reconnaissance de caractères (code postaux et chèques). La charnière a été en 2012. Avec le type de réseaux constitutionnels qui avaient le meilleur résultat de reconnaissance d’images de la base imagenet. puis, la marge d’erreurs (< à 2%) est passée sous la marge d’erreurs d’un humain. Aujourd’hui, la reconnaissance d’objet sur video (après apprentissage) fonctionne sur raspberry, la reconnaissance vocale et la modélisation (imitation) de voix devient presque parfaite.l’accélération : GPU et Big Data
La première chose qui a permis d’accélérer les capacités de calculs plus vite que les CPU sont les GPU. (architectures plus spécifiques : plus de cœurs, accès mémoire plus rapide). Ils permettent les calculs massivement parallèle avec le General Purpose Computing sur les GPU. La deuxième chose est la capacité à accumuler du big data pour permettre les apprentissages efficaces.Systèmes « experts »
Accumulation de règles « if… then… else » : trouve ses limites dans un environnement complexes et imprévisibles.Artificial Intelligence
Quand une machine semble prendre des décisions qui ressemblent à de l’intelligence. Machine Learning : Mise en place de méthodes génériques qui crée seules les règles de décision. Les outils utilisés sont : les neurones, la forward et la backward propagation, l’architecture des neurones entre eux, l’entrainement dédié et le transfert d’apprentissage (reconnaissance de chiens sert à la reconnaissance de chats). Deep Learning : Le data scientist cumule les compétences de matheux, statisticiens, visualisation, communication, en accumulation, nettoyage et réorganisation de données. La promesse du deep learning est de traiter les données comme un data scientist. Big data pipeline : Synthétiquement :- acquisition -> curation -> storage -> ETL -> analysis -> training -> prediction -> rince -> repeat -> in line (streaming) et off line (batch) -> visualisation (oui, quand même).
Machine learnings
Le Supervised Learning par exemple avec la « regression » d’un ensemble d’input pour donner un output chiffré ou un label. (« spam » pour un mail), c’est à dire une classification. L’ Unsupervised learning : recherche de cohérence automatique. Par exemple le moteur de recommandation, clustering pour la catégorisation dans Google News utilisant le Mlib appelé K-Means algo, recommendation d’achats, dimension reduction. Le Reinforcement learning : attribution de note ou de points en récompense de bonnes décisions. Exemple de la maximisation d’un score de jeu.Python
Le langage de prédilection est Python parce que :- c’est du haut niveau, sans beaucoup de cérémonies.
- le notebook jupyter est pratique pour mettre en oeuvre le langage.
- c’est un langage non typé statiquement, interprété donc lent et plante au runtime. 🙂
- ce qui est pratique, c’es le support des List, tuple, tableau multidimensionnels et surtout les slices (tranches de tableaux)
- ce n’est pas un langage confidentiel (large communauté, open-source), il dispose d’un package manager.
Mise en oeuvre
La Regression linéaire (même concept que le « reduce » de « Map Reduce »). Prenons l’exemple de l’estimation de la valeur immobilière d’un bien. On prends les différents paramètres du bien mais pour l’exemple, uniquement la superficie. On dispose d’un training set : un tableau à deux entrées avec des entrées statistiques faisant correspondre une superficie et un prix. On utilise Panda ou NumPy pour effectuer les calculs. avec les methodes polyfit ou poly1d. Imaginons que le programme de ML suppose une ligne graphique, issue de la « cost » ou « loss » function qui permettra de mesurer la distance globale entre la réalité et la fonction de courbe supposée (calculée).descente de gradient
La descente de gradient est une méthode itérative qui est la plus utilisée actuellement pour la recherche d’une modélisation. On va effectuer une descente de « gradient » en utilisant les dérivées partielles de chaque variable et en les jouant sur tous les points de la courbe supposée. Les résultats de plusieurs itérations font varier la supposition, ces résultats permettrons de fournir la meilleure courbe supposée. Les variations entre plusieurs suppositions est le « learning rate » : plus il est petit, plus c’est cher à calculer mais précis; plus il est grand, plus c’est rapide mais imprécis.forward propagation
La forward propagation est la progression de la recherche du meilleur résultat à la fin de l’utilisation du learning rate. Ce learning rate est utilisé au moment où on effectue la forward/backward propagation en changeant les gradients sur les paramètres. On surveille l’asymptote de la cost function pour trouver la solution optimale. Autre exemple : la base MNIST de 70000 chiffres écrits à la main. On réduit la matrice de pixel 28×28 en un vecteur de 784 pixels. La comparaison entre le chiffre deviné et le vrai est fait avec une fonction « softmax » qui renvoie des probabilité dont la somme est à 1. La mesure de la précision est faite en comparant le nombre de succés sur la population totale.TensorFlow
TensorFlow est le framework le plus utilisé, exploité commercialement par Google.- les placeHolders : les données en input.
- les variables : ce que TF va essayer de trouver.
- la vectorisation des calculs : « matmul » multiplication de matrices.
- tf.reduce_mean(tf.nn.softmax_cros_entropy_with_logits( labels=Y, logits=Y_ )) où les « logits » sont les « prédictions »
- définition de l’optimizer (= tf.train.GradientDescentOptimizer(alpha)), du step (= optimzer.minimize(J))
- Le nombre d' »epoch » est l’ensemble des itérations qui effectue la forward ou Backward propagation. la variable NB_EPOCHS est utilisées dans une boucle for. Celle-ci execute le session.run( step, feed_dict ).
- il est possible d’introduire un biais.
Deep Neural Network
Les opérations précédentes (softmax) sont répètées en réintroduisant un biais aléatoire à chaque fois. chaque neurones refléchie avec :- une somme pondérée
- un biais
- une fonction logistic sigmoid de descente de gradient, à la place on peut utiliser une Relu (reduced linear) qui est moins couteuse en calcul.
FAST DATA PROCESSING PIPELINE FOR PREDICTING FLIGHT DELAYS USING APACHE APIS: KAFKA, SPARK ML, DRILL, WITH MAPR-DB JSON
CAROL MCDONALD- La première partie concerne la construction d’un modèle de prédiction de délai de départ de vols « Real-Time Flight delay prediction ». Elle utilise Spark sur HBase pour affiner et conclure un modèle de prédiction par une méthode itérative.
- La deuxième partie fait la démonstration de l’utilisation du modèle de prédiction précédent dans un contexte temps réel par l’utilisation de Streams.
Construction du moteur de prediction
MapR organise le stockage en format HDFS et a forké Spark et Drill pour spécifiquement utiliser MapR et en faire une distribution complète opensource. Dans Spark 2, le RDD est remplacé par le « DataSet » et est composé lui-même de DataFrame : les « tables ». Dans un premier temps, il est pratique d’utiliser Zeppelin Notebook pour commencer un projet Big Data en dehors d’un IDE, Zeppelin permet de s’affranchir d’un IDE, d’autan que cette phase est normalement dévolue à un data scientist « non développeur » qui cherche à éviter les IDE dans la mise en œuvre de leurs recherches. C’est le même esprit que Jupyter Notebook.Zeppelin
Un projet Zeppelin permet d’attaquer un cluster spark/HBase :- en SQL avec des résultat en tableau ou en graphes.
- en Scala pour mettre en oeuvre des filtres avant requêtes.
pipeline spark
Le Pipeline Spark est composé d’une séquence de traitement :- Transformer pour mapper une colonne dans un nouvel DataFrame
- StringIndexer pour filtrer
- OneHotEncoder qui fait aussi partie du Transformer
- ensuite DecisionTreeClassifier
- enfin un *Evaluator pour comparer les prédictions et un jeu de test
Utilisation du moteur de prédiction
MapR Streams est un outils de traitement de données en streaming distribué. Le but ensuite est d’utiliser ce modèle en « temps réel » (d’un point de vue business) en mode streaming en Utilisant MapR Streams et Kafka. Kafka permet en tant qu’intermédiaire d’exposer les streams à éventuellement plusieurs consommateurs. Dans le cas de données contenues dans un fichier stocké sur disque, on utilise ProducerRecord qui lit chaque ligne d’un fichier et le projette dans un topic Kafka. Spark va consommer ce topic Kafka avec ses DStream. Le contexte est celui où le volume à traiter ne tient pas sur un seul serveur. Le besoin est celui d’une base distribuée. Alors on parle de « grosses » databases. Ainsi on peut faire des requêtes SQL sur ces données. C’est possible avec Apache Drill, avant de monter un projet de développement d’application assis sur ces données.DRILL
Drill permets d’interfacer n’importe quel type de data avec ou sans Schema, avec un front SQL, une API JDBC ou REST. Drill est téléchargeable et exécutable en standalone avec ./drill-embedded exemple :select * from file.json.gz where ...
- Il peut se poser en intermédiaire d’accès aux données hétérogènes dans la même requête car il supporte un système de table virtuelle ou des « vues ».
- Il possède des extensions à SQL-ANSI pour traiter les données répétées. (FLATTEN, KVGEN, …)
- Drill est 100% java. il peut aussi requêter des fichiers LOGS (Clever cloud l’a montré).
- Drillbit : installé sur chaque shard d’une base distribuée. il forme alors un cluster de drill.
- Drill cible l’un des noeuds et tous les Drillbit s’organisent pour répondre ensemble à la requête.
- Drill sert uniquement à l’interactif : discovery et analyse de data et BI. Il n’est pas fait pour la montée en charge comme moteur de DB pour de l’opérationnel.
storage
Kafka (et MapR Streams) peut être utilisé au delà du messaging en tant que store accessible par requêtes. HBase sur JVM utilise HDFS qui est aussi sur sa JVM, lequel écrit finalement sur le File System. Pour simplifier ce burger, MapR écrit sur le File Sytem. d’une manière compatible HDFS car très très proche d’HBase. Dernier conseil : Considérer un moteur nosql qui puisse se connecter avec Spark, Drill, Hive,…
Jeudi 17 mai : Conférences et Talks
LES DESSOUS D’UN EMBARGO DE SÉCURITÉ
STEPHEN KITTSURPRISE DU CHEF !
QUENTIN ADAMMIXOLOGY OF TECHNOLOGY IN YOUR APPLICATIONS
STEVEN POUTSYSi je me lance dans une migration vers ce nouveau framework, est-ce utile pour le projet ou seulement pour moi ? est-ce une question de comfort parce que je veux éviter de choisir un autre framework plus complexe ? Parfois la techno la plus cool n’est pas le meilleur choix, pourquoi devoir être à la mode ? Pourquoi ne pas prends une techno que je connais et sur laquelle je suis productif ? Dois-je prendre un outil surdimensionné et difficile à mettre en oeuvre pour une tache modeste qui ne le mérite pas ? le « besoin » d’une technologie est différent du « désir » d’une technologie : le besoin exige des sacrifices (apprendre, expérimenter, échouer) dans l’adoption, le désir d’adopter une techno sans besoin est souvent inutile.Le deuxième message concerne la maintenance logicielle :
Si vous avez un monolithe : laissez le tout seul, n’y touchez plus : vous créerez plus de valeurs ailleurs avec moins d’efforts et de risques.
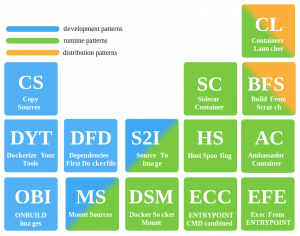
CONTAINERS PATTERNS
MARIO LORIEDO- patterns de développement,
- patterns d’exécution,
- patterns de distribution.
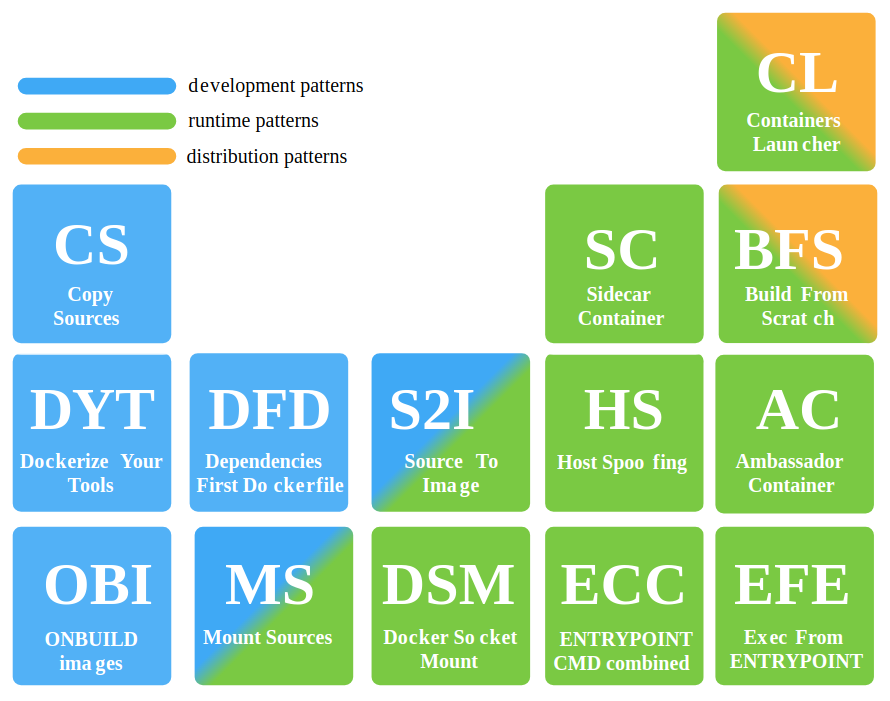 Quelques exemples :
Quelques exemples :
MS : Mount Sources (de type développement)
Lancer un container et à ce moment partager un dossier de la machine dans le container avec un mount. Permet de changer à la volée le code source et qu’il soit exécuté avec le runtime du container précédemment lancé. Ainsi ce n’est pas une bonne pratique en production. Mario montre comment avec l’appli : github/gabrielcirulli/2048 et en utilisant $docker run avec -v.DYT : Dockerize Your Tools (de type développement)
Son exemple permet de faire tourner maven en remplaçant mvn avec un alias qui lance docker run. Grâce à l’image officielle maven (3.3.3 par exemple). Permet de lancer des outils d’une autre version que celle installée sur le poste du développement. Sans avoir à changer la version locale. Pro-Tip : créer un alias pour docker ps …. et utiliser l’option –uid avec laquelle on peut lancer le container en tant qu’un user qui possède les bons droits dans le dossier local monté dans le docker.CL : Containers launcher (type runtime et distribution)
Une commande unique docker « run » lance les différents docker dépendants (mongo + App). Un fichier Dockerfile.launcher qui build à partir de l’image Alpine avec un autre docker installé dans l’Alpine. Ce container lance des scripts qui lancent d’abord le container mongo puis le container d’application. à la fin du lancement, le premier container « Launcher » s’éteint. Ceci remplace de manière plus flexible docker compose, c’est l’intérêt. C’est plus simple et plus transparent pour une topologie simple.HS : Host Spoofing (type runtime)
C’est l’exécution pour avoir des informations du host à partir du container lancé.docker run --pid=host --uts=host --ipc=host --net=host -v/:/hostfs/Il peut être utile ou nécessaire de voir tout le host à partir du container, afin de monitorer le host. On peut avoir besoin de l’adresse IP du host. Attention, Apparmor empêche ceci. C’est donc une mauvaise pratique 🙂 sauf dans des situations exceptionnelles où la config du container doit changer en fonction des ressources du host.
S2I : Source to Image (type dev et runtime par excellence)
une image JRE + maven et une deuxieme avec la JRE sans Maven. c’est un Dockerfile avec deux FROM. Le premier prépare une image qui sera copiée dans la deuxième image au moment de son build. ça s’intègre très bien avec le dockerhub, en mettant ce Dockerfile sur git.BRINGING ORDER TO THE CHAOS WITH ECLIPSE VERT.X
PAULO LOPES« shits happen… »
D’abord il rappelle que errare humanum est. exemples :- 1987 wall street crash aggravé par une sorte de DDOS (too much selling orders) coût = 500 billion $ sur la seule journée.
- 1993 : Pentium division bug : coût = 475 million $
- 1999 : le bug y2k : coût = 500 billion $
- 2018 : Spectre / meltdown, le coût sera de ?
Chaos Engineering
Il a présenté le concept de Chaos engineering qui cible le contexte de PRODUCTION. 1. On fabrique des hypothèse sur la base du Steady State Behaviour. 2. On fait varier les évènements issus du Monde Vrai. 3. On exécute les expériences en production. 4. On automatise ces expériences continuellement. 5. On tend à minimiser le blast radius. Ce Chaos engineering exige la conception d’un plan B de production pour faire face aux :- bugs
- attaques ddos
- pannes de network
- machine crashes
Reactive Manifesto
La réponse à ce processus mène vers le Reactive Manifesto :- responsive
- resilient.
- elastic
- message driven
Tooling
Comment s’équiper : les outils populaires sont :- netflix/chaosmonkey : mais des instances de cloud et une carte bancaire sont nécesssaires 😉
- l’alternative : alexei-led/pumba : plus facile à monter sur des containers locaux. Utilise docker (image gaiadocker/iproute2) to simulate network outages. Avec l’option –kill permet de tuer aléatoirement des process et simuler des crashes
- wg/wrk pour évaluer les latences et les pannes HTTP. Permet de tester les DDOS par bombardement soignés.
- iproute2 disponible dans les repos des distributions Linux. c’est la commande « ip ».
Réduction des dégâts
Comment minimiser le souffle de l’explosion, le blast radius ?- have fallback plan
- éviter l’application monolithe.
- déployer sur différents sites.
- Utiliser le pattern circuit breaker.
- Lire le awesome-chaos-engineering.
- be creative ! il n’y a pas de formule magique…
RECOMMANDATION & ELASTICSEARCH
MATHILDE LEMÉE- « Top video NRanker »
- « Tendances récentes »
- « Continue Watching »
- « parce que vous avez regardé… »
user based
le groupe est meilleur que le meilleur des individus. Ainsi les recommandations user based : c’est le rapprochement des profils et des historiques d’activité. mais c’est complexe à faire car la combinatoire users fois products est colossale.item based
La recommandation item based c’est à dire « ont aussi acheté » est seulement une matrice product fois product, c’est plus simple. Problème du cold start : au démarrage, pas de passé… pas de données. Concept de sparsity : étalement des données, d’où le besoin de large volume de données.content based
A part l’IA collaborative, c’est le content based : on compare les produits et on cherche les similarités. plus compliqué et rare : le knowledge based (immobilier) beaucoup de critère et donc difficile d’utiliser l’intelligence collective. car chaque critère est important. On peut choisir des critères sur une clé choisie (couleur du vin). une recommandation est une sorte de recherche. un critère de recherche.la classification
Etape 1 : quelles sont les catégories de mon produit ? ils ont scrappé plein de vins des sites de vente en ligne partenaires. (5000 environ). Parmi ces 5000 vins, seuls 500 avait des métadonnées cohérentes. la classification implique la construction de matrice pour catégoriser les vins, les appellations, les goûts,… Au sujet des performances du moteur : Les parents/enfants dans Elasticsearch posent problèmes car ces jointures ralentissent les recherches. Le pis-aller est la copie des parents pour accélérer l’obtention des résultats mais l’espace de stockage explose. Comment recommander sur deux catégories qui n’ont pas de résultats mises ensembles ? il faut utiliser les « boost« , et tester et mesurer les recommandation de l’un ou de l’autre des catégories. Les notes de dégustation sont des textes qui font ressortir tout un vocabulaire qui est alors classé par synonymie. problème : un vin sec qui dit trois fois dans sa description qu’il est sec ressortira avant un vin une seule fois « sec ». pour corriger, les constant score d’elasticsearch furent utilisées. création de règle de détermination de caractère de vins selon les niveaux préféré de :- sucre
- acidité
- amertume
la compléxité
les slop d’ElasticSearch : permet de détecter les proximités textuelles « peaux grasses » est mieux que « peaux normale à grasses » le scoring function_score attribue des poids a certains critères pour effectuer un scoring. function script_score un script groovy est attribué à chaque produit pour éviter les enteurs, Elasti préconise de précalculer. Le rescore permet d’optimiser le top des résultats à faible coûts. l’aggregation et les significant terms ont aussi été utilisés.1 YEAR AFTER, THEY UNDERSTOOD HOW TO CODE WITH REACTJS
GUILLAUME CRESPELLes Higher order components
les HOC sont des fonctions c’est à dire des composants et ses options. hoc-react-loader : empêche l’affichage d’un composant si il n’a pas reçu ses données k-todomvc : utlilise la lib « recompose » de react. Ainsi chaque todo porte son propre lifecyclelibrairies ReactJS
Ils ont présenté quelques librairie ReactJS intéressantes : La lib reselect permets de pointer un membre du state en particulier. La lib redux-thunk permet à un reducer de ne recevoir qu’une partie du state au moment d’envoyer des nouvelles actions. La lib k-redux-factory : une factory de reducer : set, add, remove, des selectors de state : get getKey… Best Practices : Extraire le cycle de vie et l’état du composant dans un container HOC. Un container par component (optimized). Redux utilisé en tant que key/value store. Enfin la lib k-ramel voit tous les getState et tous les dispatch. C’est un wrapper de redux et donc il le remplace.LA CRYPTO POUR LES DEVS
MATTHIAS DUGUÉ
Vendredi 18 mai : Conférences et Talks
JE ME LANCE ET DEVIENS CTO !
MATHILDE LEMÉELE COMPONENT DESIGN PAR PERCEVAL ET KARADOC : BOTTES SECRETES ET COLIFICHETS
BENJAMIN PLOUZENNECTYPOLOGIE
le composant est un élément HTML qui reçoit des props , subit un state et rend une vue. <NomComposant nomAttribut= » »/> Un composant peut être conteneur de composants. Comment on découpe un monolithe en composant ? L’atomic design. D’abord identifier les plus petits éléments répétés. Ensuite définir les molécules : rassembler les atomes de mêmes familles (userinfo=nom+avatar) le molécule est plus réutilisable Les organismes rassemblent les molécules pour donner un corps composite. (userInfo+score). Ces assemblages sont moins réutilisables Enfin le template présente les différents organismes.Design Systems
La typologie de tous ces composants est un « design system » Storybook fournit un outil de documentation de design system. exemple : http://gumdrops.gumgum.com Storybook scan le codes et génère la doc. : component +commentaires + read me Jest est un framework de test qui permet entre autres d’effectuer un snapshot testing. snapshot du dom de la page. qu’il compare si le code source a changé. Une bonne pratique est de externaliser la donnée du composant : utiliser un store qui contiendra les différents états (state) des composants. sous forme d’objet JS contenant des pairs clé/valeur Un composant pourra observer un store. Le composant pourra demander une action qui aura le droit de mettre à jour le store. Ce flux circulaire devient prédictif. Pour monitorer l’application et son store, et les events/actions, peuvent aussi requêter l’outil Sentry afin de loguer sur serveur la vie de l’application cliente.DUMB/SMART COMPONENT
dumb/smart component : Assez similaire au HOC : Higher Order Component. dumb : supprimer le state interne au componenet smart : on supprime le rendu de vue du component et remplace avec un dumb component. proposition : utiliser les webWorker pour exécuter les conteneurs de state surcharger les composants de lib de design avec un wrapper qui permettra de changer de Material à Bootstrap ou autre. Dan Abramov conseille de rester pragmatique » si vous avez besoin de store, c’est come les lunettes vous saurez quand. »10 CHOSES (QUE TOUT LE MONDE FAIT) QU’IL NE FAUT PAS FAIRE AVEC JENKINS
ADRIEN LECHARPENTIER1. curl + java run
Utiliser plutôt les packages deb, docker, yum,….2. la dernière version
Le dernier build est peut-être bugué. utilser la LTS toutes les 12 semaines.3. utiliser JENKINS_HOME
rester dans le workspace, evter les cd ../../../ la structure peut changer.4. tout sur master
risque de « rm -rf $(variable inconnue) » utiliser des agents (sur ec2, docker swarm kubernetes, jclud, ) 1 serveur == 1 agent, 1 core == 1 executeur5.Projet maven freestyle
Utiliser les pipelines car il y a problème de la copie bordelisante de job. pipeline : simple , multibranch, organization folder, script groovy presque groovy 😉 Un pipeline peut impliquer plusieurs agents dans le process. il y a des générateur de snippets pour ensuite les mettre dans les shared libraries pour factoriser les jenkinsfile. de ouf.6. garder tous les builds
jenkins n’est pas un storage de binaire, ça ralenti les graphes d’historique Aller voir l’options { builddiscarder(logrotator())}7. accès au workspace
Aucuns dans le cas pipeline. utiliser archiveArtifact. JENKINS N’EST PAS UN SERVEUR WEB. stash/unstash pour passer les builds d’un jobs à l’autre. d’un agent à l’autre et disparaît à la fin du build8. $(JENKINS_HOME) laissé à lui -même
Lui permettre de grossir, surveiller sa taille , sur un san, par exemple. mais attention : ./plugins/ à mettre sur disque rapide (ramdisk) ./war : idem ./workspace : idem9. backup tout JENKINS_HOME
Non, le quiet mode laisse atterrir jenkins et fini les builds en cours avant backup. timestamper le backup, sortir le backup du serveur.10. One jenkins to rule them all
Problème de droits (GDPR), plus on divise, multiplie les instances de plugins, plus on pourra limiter chaque config au minimum nécessaire. un jenkins pour 4-5 personnes, c’est bien.11. pas de mise à jour
Ne pas utiliser la 1.609.1 LTS. Oui mettre à jour. idem pour les plugins. idem pour la JVM. Sécurité : les credentials sont-ils dans jenkins_home ?12. downgrader en cas d’upgrade en échec
Utiliser le backup d’avant backup. tester les backups avant tout. bien sûr.13. Se plaindre du bleu qui dit « build OK »
Pourquoi le build OK est bleu ? à cause de « vert » : en japonais c’est bleu. utiliser blue ocean, puisque on fait du pipeline 🙂14. pluginmanager c’est pas utile
Si. surveiller les github des plugins pour voir si il y a de l’activité. et utiliser l’UI pour installer car il vérifie les dépendances. (ne as le faire à main en download & tar ).15. se plaindre des mauvaises performances
Lire le blog cloudbees joining big leagues yuning jenkins gc responsivenecc and stability par exemple : lui donner de la RAM. plugin « suppport core » indique les perfs de jenkins. tout est en filesystem, donc il faut du SSD.16. SSH acces denied
c’est mal, il faut un accès d’admin sur le host de jenkins pour avoir un minimum de visibilité. diagnostiquer les OOM, backuper/restore, etc…17. REST API
elle dump trop et renvoie des gros arbres et font tomber jenkins donc ajouter ces paramètres : ?tree=jobs(name)&depth=218. new way
« jenkin X » sur kubernetes. « jenkins essentials » bien pour les startups. « Configuration as a code » encore en alpha19. on peut acheter du support chez cloudbees.
Pour qu’ils puissent se nourrir (dixit).42. il faut participer à la communauté
Monter des bugs, poser des questions, voter pour les LTS, etc … Oui, il a menti dans le titre, en fait il y avait 42 choses à ne pas faire dans Jenkins.APACHE KAFKA: TURNING YOUR ARCHITECTURE INSIDE OUT
TOM BENTLEYDéfinition
Kafka : It’s mainly an horizontally scalable pub/sub message broker, where one message = one record = key & value. Non -typed.partitionning
The messages are passing through pipes names topics that are also partitionned based on : – semantic partionning (after the first letter of the key) – based on a hash de la key – round robin The partitioning is for scalability.storing
How does Kafka store messages in time : – size or time based – compacted : if an existing key arrive, it replaces the value.reading
The read action is using the offset that moves accordingly. it can be reread (rewind) to a previous offset, and messages can be skipped. There’s Consumer groups against a Kafka cluster of brokers : Consumers from different process and different machines discover each others and optimize the attribution consumer/partition, all using Kafka protocolresilience
The partions replica is about fault tolerance. The partitions are replicated on other brokers. in case of overload on a specific partition, it can be spread amongst other nodes but it can take time when the data size is big.mise en oeuvre en micro-services
Producing is easy :new KafkaProducer <>(properties, keySerializer, valueSerializer) avec Properties new ProducerRecord<>(topic, key, value)Consuming also : it’s the same :
new KafkaConsumer and ConsumerRecords<String, String> recordsFeatures of core kafka for microservices : history (audit log included), and by design loosely coupled between producers and consumers. Examples of architecture microservices
- topic order.created produced by OrderService -> consumed by StockService
- topic stock.reserved produced by StockService, -> consumed by PaymentService
- topic payment.result (success/failure) produced by PaymentService -> …
Kafka Streams
Kafka offers Kafka Streams API : events & tables « tables are events in a snapshot », (yes he said that :-). events are the lecture of a table 😉 it’s a development mode with table concepts. it’s built on top of topic api on a higher level. It supports the concept of tables as it can do aggregation and joins and windowing in case of stateful operations. in case of stateless, it’s only Streams of events. see kafka docs diagrams with KStream, Ktable, KGroupedStream, KGroupedTableJAVA CONTAINERS IN PRODUCTION – MASTERING THE « BANANA BOX PRINCIPLE »
ROLAND BRACKMANNperfect fit
Soit la JVM une banane. Une box pour banane c’est le « perfect fit » : La box, c’est un container au sens Docker. Le talk discute des problématiques de sizing de cette banana box : le cpu et la mémoire.
Pour la mémoire, il faut faire usage des ergonomics de la JVM. Initialement la JVM s’auto configure en utilisant le contexte du l’Operating System de l’hôte. Des paramètres – flags existent pour modifier ce comportement du Garbage Collector de la JVM et il est important de noter qu’ils évoluent entre la JVM 8 et la JVM 11.
De même des options Docker fonctionnent sur JVM v11 (et non sur la v8) car cette version améliore le support des cgroups de linux qui font apparaître localement des ressources globales pour la mémoire et le cpu. :
La box, c’est un container au sens Docker. Le talk discute des problématiques de sizing de cette banana box : le cpu et la mémoire.
Pour la mémoire, il faut faire usage des ergonomics de la JVM. Initialement la JVM s’auto configure en utilisant le contexte du l’Operating System de l’hôte. Des paramètres – flags existent pour modifier ce comportement du Garbage Collector de la JVM et il est important de noter qu’ils évoluent entre la JVM 8 et la JVM 11.
De même des options Docker fonctionnent sur JVM v11 (et non sur la v8) car cette version améliore le support des cgroups de linux qui font apparaître localement des ressources globales pour la mémoire et le cpu. :
- docker « –memory=500m »
- docker « –cpu-shares=2048 »
stack openshift utilisée
logstash + (java +jolokia + JBoss EAP) pour des JMX metrics vers influxdb et grafana. Où Openshift permets de killer automatiquement les JVM qui ont fait Out Of Memory. Petit give away : ContainerCoreInterceptor, openSource et permet de gérer des dumps de JVM plantées dans un container.TESTS DE CHARGE AVEC GATLING
STÉPHANE LANDELLEPourquoi
Les tests de performances sont importants : les failures coûtent de l’argent et de l’image de marque et par ailleurs, ils permettent de maîtriser les coûts de l’infrastructure. Ils permettent d’anticiper (événements), de reproduire par itération, de s’entraîner à dompter les outils de monitoring. Ces tests de charges sont à faire ensemble en interne avec les DBA, les OPS, et aussi le business qui peuvent définir les objectifs de performance. Les tests de charge évitent d’assumer les distributions des résultats (il vaut toujours mieux mesurer et décrire puis faire les stats après) Les outils à mettre en oeuvre doivent permettre de faire du provisioning de serveurs « crashable » à l’envie, de monitoring (de la JVM notamment), d’injecter des paramètres changeant à chaque itération.Quand
Les tests de charge sont en général apporteur de mauvaise nouvelles. Autant les recevoir au plus tôt. Pourquoi pas dans une démarche de tests continus ?CommenT
Gatling définie le test avec du code plutôt qu’une UI, ainsi la définition du test profite des outils de code (IDE, versioning). Oui, c’est du scala. on code avec une API type DSL (fluent c’est à dire utilise le method chaining). il propose des checks, repeat, aslongas, error handling, … il dispose de feeders de données pour nourrir les cas de tests : csv, tsv, jdbc,… Le load injector permets de partir d’un comportement réel (du navigateur et de l’utilisateur) et de l’injecter dans une configuration de test Gatling. Cela permets de simuler les sessions statefull des comportement utilisateurs en haute charge. curl, ab ou wrk (url basher) ne sont à prendre pour cette utilisation, ce sont des outils de tests de cache, en fait, pas de tests d’application. ;-), le web browser non plus. Gatling est open source, Frontline est payant et fournit des services supplémentaires de reporting principalement. L’architecture de gatling : messaging : akka, non blocking IO : netty, cette stack offre la capacité à monter en charge jusqu’à saturer la couche réseau comme un switch 1Gbs …Le reporting
Les moyennes ne servent à rien en général : où sont les peaks dans une liste de moyennes ? Les écarts types autour de la moyenne ne sont pas plus utile avec une distribution anormale (encore les peaks rodent tapis dans l’ombre, n’importe quand) Il vaut mieux utiliser des quantiles (centiles, percentiles in english) qui permet au métier d’exprimer ses exigences de performances. Il est possible de définir des critères d’acceptance qui fasse planter un build par exemple. Un plugin sur les IDE fournis un support maven /gatling avec des helpers sous forme de GUI. Une fenêtre swing apparaît on y importe les requetes exportées du navigateur pour y produire un cas de test. Il dispose aussi d’un recorder de navigation. Nota Bene : attention au mode de connexion réseaux : le handshake tls, socket open/close ou sinon en mode keepalive, tout ça peut être des goulots d’étranglement à hautes charge.UNE USINE LOGICIELLE POUR VOS WEB AGENCIES : NOTRE SOLUTION AVEC OPENSHIFT
CHARLES SABOURDINOpenshift gère Kubernetes
Les fonctionnalités recherchées étaient la faculté de faire du rolling update et la capacité a une grande résilience aux pannes. Openshift est une surcouche open source à Kubernetes, elle est promue par Red Hat et ajoute la gestion de sécurité, ce qui facilite l’adoption par les ops, chargés de la sécurité des accès sur le Systèmes d’Informations. Il empêche les images Docker de tourner en root. Openshift est donc une « distribution » de kubernetes. A noter que Red Hat contribue à au projet Kubernetes et en profite pour basculer au fur et à mesure des features d’Openshift vers kubernetes. la stack entière sur ce projet contient :- un keycloak
- des nodes labellisés
- des nodes de routeurs, des nodes d’infra
- des nodes de build
- des nodes de prod
Valeur ajoutée d’Openshift
Spécifiquement, Openshift propose- le BuildConfig (BC) instancie une image source to image permets de former une image de run à partir d’une image de build.
- l’ImageStream (IS) permet de spécifier l’image à manipuler en utilisant le tag (label) de l’image.
- le DeploymentConfig (DC) gère la stratégie de déploiement (blue-green par exemple) et de rollback (« oc rollback »). Avec un tag différent, c’est la stack de dev ou celle de prod qui est déployée par le même DC.
- PersistenceVolumeClaim (PVC) pour réserver un PersistenceVolume (PV) (avec « oc volume ») permet de disposer des ressources du cluster NFS, clusterFS, … partagé entre les pods.
retours d’expériences
Les PV : ils ont constatés des blocages IO avec le volume NFS. De plus ils étaient en aveugle sur l’état du volume car openshift ne voit pas la capacité maximale. les concepts de containers docker. Il était nécessaire de monter des alertes parallèles par cron + script ($ df) pour surveiller l’espace disque. La documentation Openshift suppose que la documentation kubernetes ait été lue et comprise 🙂 Elle est peut être ainsi absconse si on n’y est pas préparée. les gains :- Traçabilité de l’architecture
- Réactivité dans la minute.
- Sécurité (facilité de planification d’application de patch de sécurité sur les images)
- source-to-image était un plus prépondérant par rapport à Kubernetes
Conclusion personnelle
Suivre les conférences comme RivieraDev est très important pour plusieurs raisons :- s’informer de l’état de l’art dans différents domaines qui ont en commun de beaucoup bouger d’une année à l’autre.
- recueillir des retours d’expériences auprès des speakers et des autres auditeurs.
- acquérir des bases dans un domaine inconnu afin de pouvoir se lancer sans se disperser.
- évaluer la complexité d’un domaine pour déterminer ses besoins en formation ou support.
- manger des pan bagnats et de la socca en écoutant du Muse.
